

در برنامهنویسی به زبانهای مختلف برای یافتن بخشهایی از متن که الگوی خاصی دارد، از عبارتهای منظم یا به اختصار Regex استفاده میشود. ممکن است در برنامهنویسی یک اپلیکیشن یا بازی و یا سایت، برای جایگزین کردن بخشهایی از متن، تأیید ورودی، تغییر فرمت متن و بسیاری امور دیگر از Regex استفاده شود. البته کاربرد ریجکس به برنامهنویسی محدود نمیشود بلکه در برخی نرمافزارهای ویرایش متن هم امکان استفاده از عبارتهای منظم به منظور جستجو یا جستجو و جایگزین کردن برخی عبارتها وجود دارد.
در این مقاله با مفهوم عبارتهای منظم و شیوهی استفاده از آن آشنا میشویم. این موضوع حتی برای کاربران یا برنامهنویسان مبتدی نیز مفید است. ما را در ادامهی مطلب همراهی کنید.
عبارت منظم یا Regex چه کاربردی دارد؟
فرض کنید که یک فایل متنی طولانی دارید و میخواهید در آن کلمهی Ali Reza را پیدا کرده و به جای آن Alireza را جایگزین کنید. کافی در نرمافزاری نظیر Notepad++ کلید میانبر Ctrl + F را برای سرچ کردن متن فشار دهید و در پنجرهی جستجو، سراغ تب Search and Replace یا جستجو و جایگزی کردن بروید. سپس عبارت موردنظر و جایگزین آن را تایپ کنید.
اما به مثال دوم توجه کنید:
فرض کنید در فایل متنی نام خویش را به شکلهای مختلفی و به صورت اشتباه تایپ کردهاید:
- AliReza
- Ali-Reza
- Ali Reza
- Ali Reza
- Ali- -Reza
- Ali2Reza
- AlirReza
و میخواهید همهی حالتها را با کلمهی درست جایگزین کنید. اولین راهی که به ذهن هر کاربری میرسد، چند بار استفاده از ابزار جستجو و جایگزینی است. کار وقتگیری است! راهکاری که یک برنامهنویس یا کاربر آشنا به ریجکس پیشنهاد میکند، استفاده از عبارت منظمی است که همهی حالتهای فوق را پوشش بدهد. به عنوان مثال عبارت منظم زیر معادل این است که بین کلمهی Ali و Reza یک یا چند کاراکتر دلخواه وجود دارد که دقیقاً برایمان مشخص نیست:
Ali(.+)Reza
و میتوانید عبارت جایگزین را Alireza تعریف کنید. در این صورت ابزار جستجو و جایگزین کردن، همهی حالتهایی که مثال زدیم را در متن پیدا کرده و به جای آن Alireza قرار میدهد. حتی حالتهایی که در متن موجود است و دقیقاً به خاطر نمیآوریم، تصحیح میشود.
آشنایی با تطبیق عبارتها به کمک Regex
منظور از عبارت منظم یا Regular Expression که به اختصار Regex گفته میشود، الگویی است که به موتور پردازش Regex داده میشود تا عبارتهای منطبق با آن را شناسایی کند و در ادامه فرآیندی مثل تأیید ورودی ، جایگزین کردن متن، استخراج بخشهایی از ورودی برای پردازشهای بعدی و غیره انجام شود. در مثالی که زدیم، هدف سرچ کردن و جایگزین کردن بود اما کاربردهای متنوعی وجود دارد.
سینتکس استفاده از عبارتهای منظم در نرمافزارها و برنامهنویسی به زبانهای مختلف، گاهی به نظر بسیار پیچیده و بههمریخته است به طوری که کاربر از فراگیری آن منصرف میشود. نمونهی زیر یک ریجکس عمومی برای تأیید کردن آدرس ایمیل است:
(?:[a-z0-9!#$%&'*+/=?^_`{|}~-]+(?:\.[a-z0-9!#$%&'*+/=?^_`{|}~-]+)*|"(?:[\x01-\ x08\x0b\x0c\x0e-\x1f\x21\x23-\x5b\x5d-\x7f]|\\[\x01-\x09\x0b\x0c\x0e-\x7f])*") @(?:(?:[a-z0-9](?:[a-z0-9-]*[a-z0-9])?\.)+[a-z0-9](?:[a-z0-9-]*[a-z0-9])?|\[(? :(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0- 9][0-9]?|[a-z0-9-]*[a-z0-9]:(?:[\x01-\x08\x0b\x0c\x0e-\x1f\x21-\x5a\x53-\x7f]| \\[\x01-\x09\x0b\x0c\x0e-\x7f])+)\])
اگر با ریجکس آشنایی نداشته باشید احتمالاً تصور میکنید که کسی کلیدهای کیبورد را سریع و تصادفی فشار داده است تا عبارتی تصادفی تایپ کند. اما در حقیقت این یک عبارت منظم است که برای برنامه دادن به یک ماشین و مشخص کردن قواعد آنالیز متن نوشته شده است.
در توضیح عبارتهای منظم سایتها و نرمافزارهای زیادی طراحی شده و بعضاً مراحل پردازش یک عبارت منظم را با فلوچارت و نمودارهای ساده به تصویر میکشند.
اما در نهایت درک کردن مفهوم عبارتهای منظم طولانی، در شروع کار ساده نخواهد بود.
استفاده از سایتهای Regex Debugger
برای بررسی ریجکسهای طولانی بهتر است از ابزارهای آنلاین استفاده شود مگر آنکه بسیار ماهر و سریع باشید. میتوانید در برخی سایتها نظیر Regex101 یا RegExr، عبارت منظم را وارد کنید و متنی را برای یافتن بخشهایی که منطبق بر الگو است، وارد کنید. در این سایتها بخشهای مختلف رنگارنگ میشود و درک کردن مفهوم یک عبارت منظم پیچیده، سادهتر میشود. به علاوه اشارهای مختصر به سینتکسها شده که برای مبتدیان مفید است.
ریجکس چطور کار میکند؟
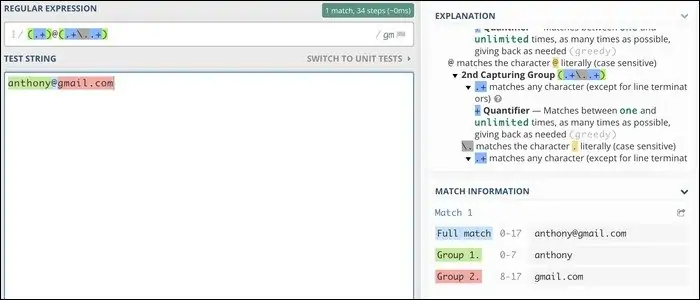
به یک مثال ساده میپردازیم که تأیید کردن آدرس ایمیل است، البته نه مثل نمونهی کاملی که اشاره کردیم. یک آدرس ایمیل معمولی به چند بخش تقسیم میشود:
- یک یا چند حرف
- نماد @
- پس از آن یک یا چند حرف که نام دامنه است
- کاراکتر . یا نقطه
- و در نهایت پسوند دامنه
عبارت منظم برای این ساختار ساده، عبارت زیر است:
(.+)@(.+\..+)
این ساختار در تصویر زیر به شکل گرافیکی نیز توصیف شده است:
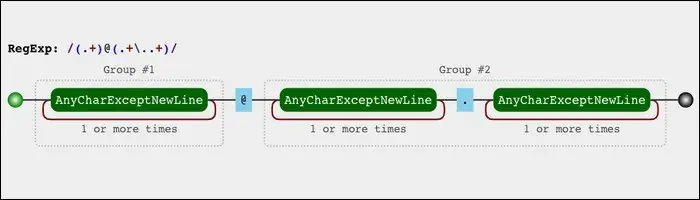
اما توضیحی در مورد نحوهی پردازش ریجکس فوق: موتور ریجکس از سمت چپ آغاز میکند و گروهها را یکییکی تطبیق میدهد. گروه اول در این ریجکس، نام کاربری است که قبل از نماد @ ذکر میشود. عبارت زیر در ابتدای ریجکس، نام کاربری را تعریف میکند:
(.+)
پرانتز شروع و پایان برای مشخص کردن گروه اول به کار رفته و به موتور پردازش ریجکس میگوید که مقدار این گروه را در یک متغیر ذخیره کند. ممکن است برنامهنویس بخواهد در ادامهی برنامه، از گروه اول برای کار خاصی استفاده کند.
حال اگر یک آدرس فرضی ایمیل به برنامهای که این ریجکس در آن به کار رفته بدهید، بخش قبل از @ همان گروه اول خواهد بود که در متغیر اول ذخیره میشود. به عنوان مثال در مورد آدرس ایمیل زیر:
%$#^&%*#%$#^@gmail.com
اولین گروه عبارت %$#^&%*#%$#^ خواهد بود.
اما توضیح بیشتر در مورد مفهوم دو سینتکس + و . در گروه اول:
- نماد + به معنی تطبیق با کاراکتر یا گروه قبل از آن به تعداد ۱ مرتبه یا بیشتر است.
- سینتکس . معادل یک کاراکتر که هر کاراکتری میتواند باشد، البته به جز خط جدید
لذا عبارت .+ به معنی یک کاراکتر یا بیشتر است. اگر از + استفاده نمیشد، گروه اول تنها با اولین کاراکتر از نام ایمیل تطبیق پیدا میکرد.
حال سراغ ادامهی ریجکس مثالمان میرویم. پس از نماد @، یک گروه دیگر وجود دارد:
(.+)@(.+\..+)
در گروه دوم هم یک یا چند کاراکتر در شروع وجود دارد و به نقطه ختم میشود و پس از نقطه، یک یا چند کاراکتر دیگر موجود است. با توجه به اینکه . همان نقطهی معمولی نیست بلکه یک سینتکس با معنایی متفاوت است، برای تعریف کردن نقطهی معمولی میبایست قبل از آن از نماد \ استفاده کرد. به همین ترتیب برای ذکر ) و ( و + و چندین حرف خاص دیگر، میبایست ابتدا از \ استفاده کرد تا به عنوان سینتکسهای ریجکس شناسایی نشوند.
بنابراین مفهوم عبارت زیر، همان نقطهی معمولی است:
\.
در حالی که عبارت زیر معادل یک کاراکتر دلخواه به جز خط جدید است:
.
و این دو کاملاً متفاوت هستند.
معرفی کاراکترها در عبارتهای منظم
اگر در عبارت منظم از کاراکترهای غیرکنترلی استفاده شده باشد، موتور پردازش ریجکس فرض میکند که کاراکترهای ذکر شده، بلوکی است که باید تطبیق داده شود. به عنوان مثال ریجکس زیر:
he+llo
با کلمات hello و heello و heeello و هر تعدادی e در میان کلمهی hello تطبیق دارد چرا که پس از e از + استفاده شده است. لذا کلمهی hello با یک یا هر تعداد e مطابق با ریجکس فوق خواهد بود.
به جز . که به مفهوم آن اشاره کردیم، چند کلاس کاراکتر دیگر نیز وجود دارد:
- \w معادل هر کلمهای حاوی حروف و ارقام است.
- \d معادل هر عددی است.
- \b معادل کاراکترهای فاصلهگذاری نظیر اسپیس و تب و خط جدید است.
این سه کلاس کاراکتر در صورت نوشته شدن با حرف بزرگ، عمل عکس انجام میدهند. به عنوان مثال D به معنی هر چیزی به جز عدد است!
میتوانید عبارتی که با مجموعهای از حروف یا اعداد تطبیق دارد را نیز پیدا کنید. به عنوان مثال عبارت زیر با کاراکتری که a یا b یا c باشد، تطبیق پیدا میکند:
[abc]
میتوانید به جای ذکر کردن همهی کاراکترها، محدودهای را ذکر کنید. عبارت زیر معادل عبارت فوق است:
[a-c]
و عبارت زیر معادل اعداد ۱ و ۲ و ۳ و ... الی ۸ است:
[1-8]
حالت معکوس نیز با نماد ^ قابل تعریف کردن است. به عنوان مثال عبارت زیر معادل هر کاراکتری به جز حرف a الی c است:
[^a-c]
شمارندهها در ریجکس
بخش مهم دیگری از سینتکس عبارتهای منظم، شمارندهها است. قبلاً به + اشاره کردیم که شمارندهای به معنی ۱ یا بیشتر است. به عنوان مثال عبارت زیر با هر رشتهای حاوی حروف و اعداد که بیش از یک کاراکتر داشته باشد، تطبیق پیدا میکند:
\w+
و اما چند اپراتور شمارندهی دیگر در عبارتهای منظم:
- * به معنی صفر یا بیش از صفر مورد است. در واقع * مشابه + است با این تفاوت که حالت ۰ تطبیق را نیز شامل میشود.
- ? به معنی صفر یا یک مورد است. به عبارت دیگر وجود کاراکتر قبل از آن در متن را اختیاری میکند. یا کاراکتر پیدا میشود و یا وجود ندارد. اگر چند بار وجود داشته باشد، فقط مورد اول تطبیق داده میشود.
- عدد داخل گیومه نظیر {4} به معنی ۴ بار تکرار شدن کاراکتر قبل از آن است.
- مجموعه اعداد یا محدودهی اعداد داخل گیومه نظیر {1-3} به معنی حداقل و حداکثر تعداد کاراکتر است. این مثال خاص به معنی وجود ۱ الی ۳ مورد است.
- اگر داخل گیومه عدد دوم را وارد نکنید، حداکثر تعداد نامحدود خواهد شد. به عنوان مثال {1,} به معنی وجود یک مورد یا بیشتر است و دقیقاً با شمارهی + که به آن اشاره کردیم، یکسان است.
محدودکنندهها
همانطور که اشاره کردیم اپراتورهای + و *، برای تطبیق کاراکتر یا گروه با حداقل یک و صفر مورد به کار میروند اما حداکثر تعداد تطبیق، نامحدود است. ممکن است نامحدود بودن تطبیقها مشکلساز باشد. لذا به اپراتورهای محدودکننده نیاز داریم.
به عنوان مثال فرض کنید در کد HTML یک صفحهی وب، عبارت زیر موجود است:
<div>Hello World</div>
و میخواهید اولین تگ div را با نوشتن جاوااسکریپت سادهای، تغییر بدهید و کلاس یا آیتی به آن اضافه کنید. اگر از عبارت منظم زیر برای تطبیق با <div> ابتدایی استفاده کنید، با مشکل روبرو میشوید:
<(.*)>
در واقع گروه اول موجود در ریجکس فوق که .* است، با عبارت div>Hello World</div> تطبیق پیدا میکند. علت بروز مشکل، نامحدود بودن تطبیقها در صورت استفاده از اپراتور * است.
اما چاره چیست؟ میبایست از اپراتور محدودکننده ? استفاده کنید. در این صورت به محض یافتن اولین تطبیق، کار متوقف میشود. لذا در صورت استفاده از ریجکس زیر:
<(.*?)>
گروه اول عبارت div خواهد بود. نکتهی جالب این است که میتوانید اپراتور محدودکننده ? را پس از شمارندههای دیگر نیز استفاده کنید. به عنوان مثال میتوانید از +? یا {0,3}? و حتی ?? استفاده کنید که البته مورد آخر اثر خاصی ندارد چرا که به هر حال صفر یا یک مورد تطبیق شناسایی میشود.
گروهها در Regex
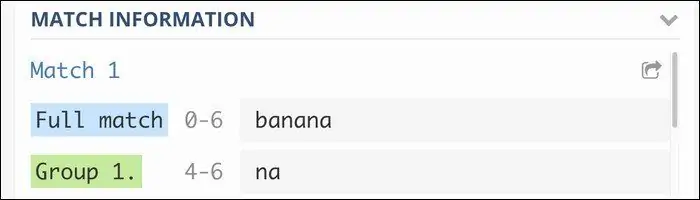
همانطور که در ابتدای مقاله اشاره کردیم، استفاده از گروهها کاربردهای فراوانی دارد و یک نمونهی آن، جایگزین کردن بخشهایی از متن است. میتوانید گروهی که تعریف شده را با استفاده از شمارندهها به تعداد موردنیاز پیدا کنید. به عنوان مثال ریجکس زیر را در نظر بگیرید:
ba(na)+
این ریجکس با هر عبارتی که با ba شروع شود و به دنبال آن یک یا تعداد نامحدودی na وجود داشته باشد، تطبیق پیدا میکند. لذا bananana و banana الگویی مطابق با ریجکس فوق دارد.
به این نوع گروه که با پرانتز سادهی شروع و خاتمه پیدا میکند، Capture Group گفته میشود و میتوانید از آن در خروجی استفاده کنید.
اگر در خروجی به گروه نیاز ندارید، میتوانید گروه آزاد تعریف کنید. به مثال زیر توجه کنید:
ba(?:na)
در این حالت هم na یک گروه است اما با وجود علامت سوال قبل از آن، یک گروه غیراستاندارد است.
میتوانید گروهها را نامگذاری کنید و در ادامهی ریجکس از گروهی که قبلاً نامگذاری کردهاید استفاده کنید:
(?'group')
برای ارجاع دادن به گروههایی که نامگذاری نشدهاند، میبایست از اعداد ۱ الی ۷ به شکل \1 الی \7 استفاده کنید اما برای تعداد بیشتر میبایست از روش نامگذاری استفاده کنید.
سینتکس ارجاع به گروههایی که نامگذاری شدهاند به صورت زیر است:
\k{group}
به عنوان مثال اگر بخواهید عبارت منظمی بنویسید که در آن یک عبارت سه مرتبه تکرار شده است، مورد اول را پیدا کرده و نامگذاری میکنید و سپس در موقعیتهای بعدی به آن ارجاع میدهید. نتیجه ایجاد یک گروه با محتوای دینامیک است. به مثال زیر توجه کنید:
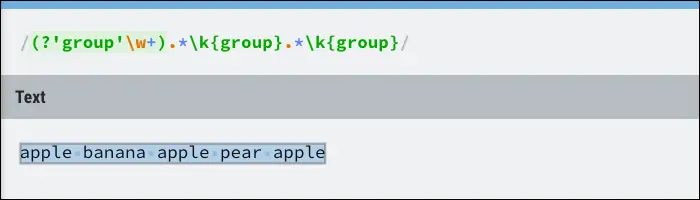
تفاوت بین موتورهای ریجکس
متأسفانه تمام موتورهای پردازش Regex به یک شیوه عمل نمیکنند! و یک استاندارد واحد وجود ندارد. برخی قابلیتها و سینتکسها که در یک زبان ریجکس پشتیبانی میشود و مفهوم خاصی دارد، در زبان دیگری پشتیبانی نمیشود یا مفهوم آن متفاوت است!
به عنوان مثال در ورژنی از sed که برای macOS و FreeBSD کامپایل شده، نمیتوانید از \t برای اشاره به کاراکتر تب استفاده کنید بلکه میبایست به صورت دستی یک کاراکتر تب را کپی کرده و در ترمینال پیست کنید.
بیشتر آموزشهای مرتبط با Regex با PCRE سازگار است که موتور پیشفرض پردازش Regex در زبان PHP است. موتور پردازش ریجکس در جاوااسکریپت و ریجکس Perl و سایر موارد متفاوت هستند. خوشبختانه در برخی سایتهای دیباگ کردن ریجکس نظیر Regex101، امکان انتخاب کردن موتور ریجکس وجود دارد. لذا دقت کنید که موتور پردازش ریجکس را صحیح و متناسب با زبان برنامهنویسی انتخاب کنید.
استفاده از ریجکس
نحوهی تطبیق دادن عبارتها با Regex را به صورت مفید و مختصر توضیح دادیم اما در نهایت برای اجرا کردن یک فرآیند، میبایست عبارت منظم را کامل کنید. سینتکس عمومی یک عبارت منظم کامل به شکل زیر است:
/match/g
آنچه بین دو اسلش ذکر شده، عبارت تطبیقی است. حرف g در انتها موجب میشود که موتور پردازش ریجکس با یافتن اولین تطبیق، متوقف نشود بلکه تمام متن را بررسی کند.
برای جستجو و جایگزین کردن یک عبارت، میبایست از سینتکس زیر استفاده کنید:
/find/replace/g
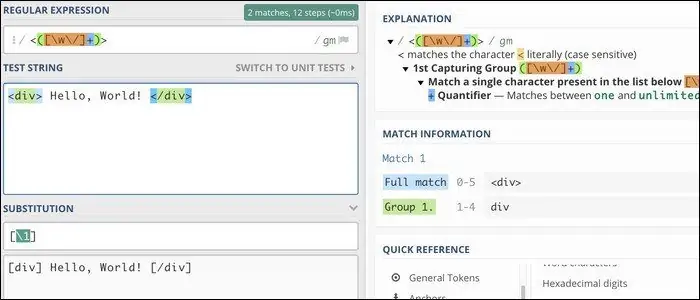
به عنوان مثال اگر بخواهید در یک فایل HTML تمام تگها را پیدا کرده و به جای < و > کاراکتر [ و ] را جایگزین کنید، میتوانید از ریجکس زیر استفاده کنید. در این ریجکس عبارت \1 برای ارجاع به اولین گروه که محتویات بین < و > است، به کار رفته است:
/<(.+?)>/[\1]/g
نتیجه را در تصویر زیر مشاهده میکنید:
تفاوت Wildcard با Regex
همانطور که اشاره کردیم از ریجکس برای معرفی الگو به موتور پردازش ریجکس استفاده میشود و هر عبارتی که مطابق با آن باشد، به عنوان نتیجه، پیدا میشود. اما منظور از Wildcard، کاراکترهای احتمالی است که چند حالت مختلف دارد. به عبارت دیگر برای اشاره به یک کاراکتر که دقیقاً مشخص نیست، از وایلدکاردها استفاده میشود. تعریف کردن ساختار به کمک Wildcard امکانپذیر است اما توانمندی Regex به مراتب بیشتر است.
به عنوان مثال زمانی که میخواهید کدهایی در ترمینال لینوکس اجرا کنید و فایلهایی با نامهای متنوع که ابتدا با حرف a آغاز شده و سپس یک یا چند کاراکتر دیگر وجود دارد و در نهایت پسوند txt است، میتوانید از Wildcard استفاده کنید.
a*.txt
در عبارت فوق * برای اشاره به کاراکترهای احتمالی به کار رفته است.
همانطور که اشاره کردیم Wildcard بسیار مفید و کاربردی است اما در عین حال به مراتب سادهتر از ریجکس است. البته وایلدکارد نیز شامل چند نماد مختلف میشود که معنای متفاوتی دارند. به جدول زیر توجه کنید:
| نماد | مفهوم | نمونه مثال کاربردی |
|---|---|---|
| * | صفر کاراکتر یا بیشتر | *bl عبارات bl ،black ،blue و blob را پیدا میکند. |
| ? | یک کاراکتر دلخواه | h?t عبارات hat ،hot و hit را پیدا میکند. |
| [] | یکی از کاراکترهای ذکر شده داخل براکت | h[oa]t عبارات hat ،hot را پیدا می کند اما hit را خیر |
| ! | کاراکترهایی به جز آنچه ذکر شده | h[!oa]t عبارت hit را پیدا می کند اما hot و hat را خیر |
| – | اشاره به محدودهای از کاراکترها | c[a-b]t عبارات cat و cbt را پیدا میکند |
| # | کاراکتری از نوع عدد | 2#5 اعداد 205 و 215 و 225 و … را پیدا میکند. |
cloudsavvyitسیارهی آیتی