

ایجاد عدد تصادفی حین اجرا کردن دستورات یا اسکریپتنویسی Bash، کار سادهای است. میتوانید از متغیری به اسم RANDOM استفاده کنید. اما سوال این است که آیا عددی که ایجاد میشود واقعاً تصادفی است؟ آیا راهی برای بهبود الگوریتم ایجاد عدد تصادفی وجود دارد؟
در این مقاله به متغیر RANDOM و ایجاد عدد تصادفی در Bash میپردازیم.
ایجاد عدد تصادفی در ترمینال
حین نوشتن برخی برنامهها یا اسکریپتها، برای انتخاب کردن یکی از چند گزینه یا یکی از عناصر آرایه، به عدد تصادفی نیاز داریم. در ترمینال لینوکس یا به عبارت دیگر زبان Bash میتوانید از $RANDOM برای ایجاد عدد تصادفی استفاده کنید. در واقع RANDOM نام یک متغیر معمولی نیست بلکه عددی تصادفی ایجاد میکند. به عنوان مثال اگر دستور echo و سپس این متغیر را وارد کنید، هر بار یک عدد تصادفی در ترمینال چاپ میشود.
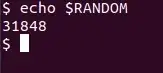
حتی اگر به این متغیر مقداردهی کنید هم حین چاپ یک عدد تصادفی ظاهر میشود. اما مسأله این است که آیا $RANDOM یک عدد واقعاً تصادفی است؟ به تصویر زیر نگاهی بیاندازید:
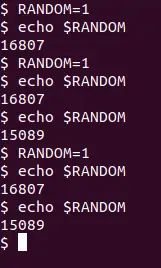
همانطور که میبینید در چند مرتبه استفاده از این متغیر، اعداد تصادفی تکراری ایجاد شده که عجیب است. در واقع عددی که ایجاد میشود به این بستگی دارد که چه seed یا مقدار اولیهای به تابع ایجاد عدد تصادفی بدهید. با توجه به اینکه در این مثال، عدد ۱ را به عنوان ورودی به تابع دادهایم، عدد تصادفی ایجاد شده، فقط چند حالت خاص دارد و تکرار دیده میشود.
اما چاره چیست؟
یک راهکار ساده که شاید به ذهن شما هم رسیده این است که یک عدد تصادفی به عنوان ورودی به تابع ایجاد عدد تصادفی بدهیم و در واقع دو بار از این تابع استفاده کنیم. میتوانیم $RANDOM در در متغیر RANDOM بریزیم و آن را به تابع بدهیم. اما نتیجهی کار به مقدار ورودی اولیه بستگی پیدا میکند و باز هم عدد واقعاً تصادفی ایجاد نمیشود. به تصویر زیر توجه کنید:
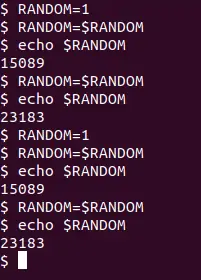
به نظر میرسد که تنوع اعداد تصادفی بیشتر شده اما این تنوع کافی نیست. اگر سه بار از تابع ایجاد تصادفی به صورت سری استفاده کنید هم تعداد حالتها بیشتر میشود ولیکن باز هم مشکل پابرجاست.
مشکلی که با آن سروکار داریم، یک اشکال معروف به اسم انتروپی تصادفی است. مشکل Random Entropy نه فقط در Bash بلکه در سایر سیستمهای پایهای کامپیوتر جهت ایجاد عدد تصادفی وجود دارد. لذا عدد رندم هیچگاه واقعاً رندم نیست! الگوریتمهای قدیمیتری برای ایجاد عدد تصادفی وجود داشته که از رویدادهایی نظیر حرکت موس یا فشار دادن کلیدهای کیبورد استفاده میکرده و حاصل کار ایجاد عدد تصادفیتری بود.
اما سوال و مسألهی امروز ما این است:
چگونه عدد تصادفی که به قدر کافی خوب باشد، ایجاد کنیم و به آن عدد واقعاً تصادفی بگوییم؟
برای این مهم به یک ورودی نسبتاً تصادفی نیاز داریم. به عنوان مثال تاریخ که البته چندان هم تصادفی نیست. شاید بهتر باشد که تاریخ را به صورت تعداد ثانیهها از اولین روز و اولین ماه سال ۱۹۷۰ در نظر بگیریم. اما اگر به جای ثانیه از نانو ثانیه استفاده کنیم چطور؟ در این صورت ورودی واقعاً رندم میشود، نه؟
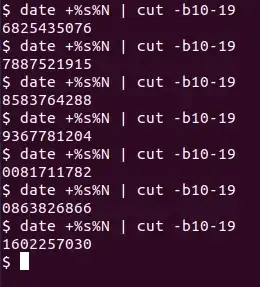
لذا پیشنهاد ما استفاده از آخرین رقم زمان بر حسب نانوثانیه است. به عبارت دیگر باید با تابع data، تاریخ و ساعت و ثانیه و نانوثانیه را برآورد کنید و سپس چند رقم اول را حذف کنید. به دستورات زیر توجه کنید که در آن ورودی تابع ایجاد عدد تصادفی، بخشی از عدد زمان بر حسب نانوثانیه است:
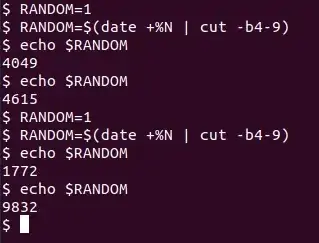
در این الگوریتم ابتدا تابع date، زمان را محاسبه میکند و سپس بایتهای ۴ الی ۹ خروجی این تابع که ۶ رقم است، به عنوان ورودی تابع ایجاد عدد تصادفی در نظر گرفته میشود. در نهایت $RANDOM عدد تصادفی ایجاد میکند.
البته این الگوریتم هم انتخاب کاملی نیست اما بهتر از الگوریتم پیشفرض است. مشکل این الگوریتم از این جهت است که میتوان اعداد بین ۰ و ۹۹۹۹۹۹ را به تابع ایجاد عدد تصادفی داد و همهی حالتهای خروجی را به دست آورد. طبعاً پیدا کردن همهی حالتهای خروجی، در فرآیند رمزگشایی یا کشف کلید رمزگذاری، گام مهمی است که به درد هکرها میخورد.
اگر تعداد ارقامی که به تابع ایجاد عدد تصادفی میدهیم را بیشتر کنیم، طبعاً ریسک امنیتی کاهش پیدا میکند. اما باید این نکته را هم در نظر گرفت که در صورت افزودن تعداد ثانیهها پس از اولین روز سال ۱۹۷۰، میزان تصادفی بودن ورودی اولیه، کاهش پیدا میکند که چیز خوبی نیست.
به نظر میرسد که استفاده از نانوثانیه در برنامههای سادهای که به عدد تصادفی نیاز داریم، کافی است و خروجی کار واقعاً رندم است اما برای کارهای پیچیدهتر که عدد باید واقعاً تصادفی باشد، این راهکار مناسب نیست. در این صورت باید از سختافزاری خارجی که برای ایجاد عدد تصادفی بهینه شده، استفاده کرد که نتیجهی بهتری به دنبال دارد. به هر حال پدیدههای طبیعی مثل لرزش موس، حالت تصادفیتری نسبت به الگوریتمهای کامپیوتری دارند.
cloudsavvyitسیارهی آیتی