

اغلب تحلیلگران آمار برای تحلیل کردن دادههای جمعآوری شده از نرمافزارهای تخصصی آمار استفاده میکنند. در Excel مایکروسافت نیز ابزاری برای آنالیز دادههای آماری وجود دارد که مقادیری مثل میانگین، پراکندگی داده و انحراف معیار و حتی تستهای پرکاربری مثل تست T و محاسبهی رگرسیون و ضریب همبستگی یا Correlation Coefficient را به سادگی انجام میدهد.
مایکروسافت اکسل برای تحلیل آمار طراحی نشده اما با وجود ابزارهای کمکی برای تحلیل آمار که در حالت پیشفرض غیرفعال است، انتخاب دوم محسوب میشود و میتوان در مواقع خاص از آن استفاده کرد.
در این مقاله به روش فعال کردن افزونهی Data Analysis Toolpak اکسل و استفاده از آن برای مقایسه و تحلیل دادههای آماری میپردازیم. با سیارهی آیتی همراه شوید تا اکسل را کاملتر از قبل بشناسیم و به کار بگیریم.
فعال کردن ابزار آنالیز آماری داده در اکسل یا Excel Data Analysis
برای فعالسازی ابزار تحلیل دادهای که در اکسل ۲۰۱۶ پیشبینی شده، ابتدا روی منوی File کلیک کنید و سپس از ستون کناری، Options را انتخاب کنید. در پنجرهی Excel Options نیز از ستون سمت چپ Add-ins را انتخاب کنید.
اکنون در سمت راست و در پایین صفحه، روی دکمهی Go در کنار فیلد Manage کلیک کنید. توجه کنید که از منوی کرکرهای گزینهی Excel Add-ins انتخاب شده باشد و نه گزینهی دیگری.
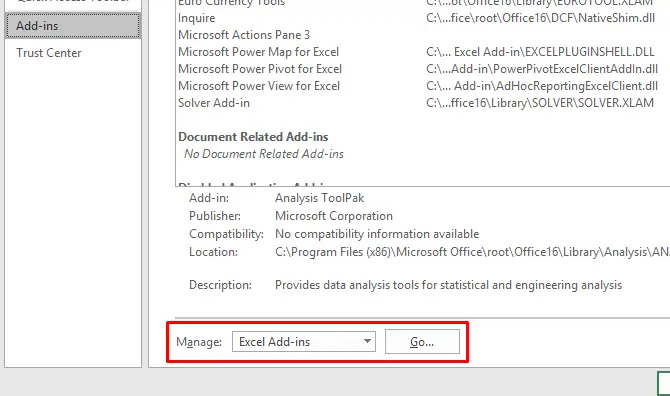
در پنجرهای که نمایان شده، تیک گزینهی Analysis Toolpak را بزنید و سپس روی OK کلیک کنید. Analysis Toolpak بستهای حاوی ابزارهای مربوط به آنالیز و تحلیل داده است که در ادامه با چند قابلیت جالب آن آشنا میشویم.
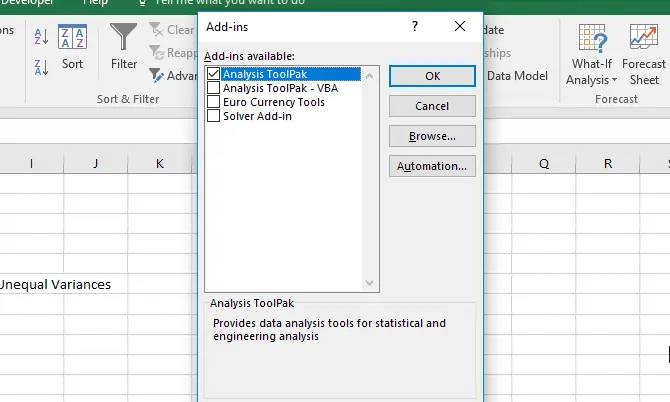
اگر مراحل را به درستی انجام داده باشید، گزینهی جدید و بخش جدیدی در تب Data اضافه میشود. روی تب Data در بالای پنجرهی اکسل کلیک کنید و توجه کنید که بخش Analysis حاوی ابزار Data Analysis در انتهای آن اضافه شده است.
افزونه یا Add-in فعالشده، تنها یکی از افزونههای آنالیز داده برای Excel مایکروسافت است و در حقیقت میتوان از افزونههای دیگری نیز استفاده کرد تا تحلیل داده، پردازش و آنالیز و ایجاد نمودارها و گزارشهای گرافیکی را ساده و حرفهای میکنند. اگر از اکسل برای تحلیل داده استفاده میکنید، بد نیست کمی گوگل کنید و افزونههای موجود و قابلیتهای هر یک را بررسی نمایید.
اگر افزونهی Analysis Toolpak را از روشی که مطرح کردیم، فعال کرده باشید، نیازی به استفاده از فرمول و محاسبات به کمک توابع اکسل ندارید و همهچیز ساده و سریع محاسبه میشود. روش کار با انواع تحلیلهای این ابزار به این صورت است:
ابتدا در تب Data بالای صفحه، روی Data Analysis کلیک کنید.
در پنجرهی انتخاب نوع آنالیز، مورد دلخواه خود را انتخاب کنید و روی OK کلیک کنید.
محدودهای که اعداد و آمار را وارد کردهاید با کلیک کردن روی سلول ابتدا و درگ کردن تا آخرین سلول، انتخاب کنید.
کلید Enter را فشار دهید و یا روی فلش به سمت پایین در فیلد انتخاب ورودی کلیک کنید.
اگر به لیبل یا برچسب برای دادههای خود نیاز دارید، تیک چکباکس Labels که در تصویر فوق مشاهده میکنید را اضافه کنید.
میتوان خروجی را در یک صفحهی کاری یا Worksheet جدید در اکسل ذخیره کرد و همینطور میتوان خروجی را در صفحهی فعلی قرار داد. استفاده از ورکشیتهای متعدد در اکسل، نظم و سرعت کار را بیشتر میکند:
آمار در اکسل به همراه متوسط، پراکندگی و انحراف معیار و خطا و ...
در اغلب بررسیهای آماری که به کمک نرمافزار Excel مایکروسافت انجام میشود، چند پارامتر ساده و مفید را لازم داریم. دانستن مقدار متوسط تعدادی عدد یا Mean، عددی که در وسط دنبالهی اعداد قرار گرفته یا Median، واریانس که پراکندگی دادهها را نشان میدهد و همینطور انحراف معیار یا Standard Deviation و خطا یا Error، همگی برای کسی که مرتباً دادههای آماری را تحلیل و بررسی میکند، مفید و ضروری است.
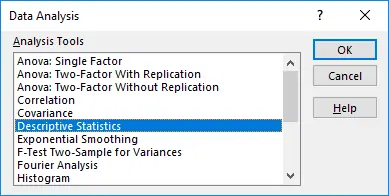
ابتدا در تب Data بالای صفحه، روی Data Analysis کلیک کنید.
در پنجرهی انتخاب نوع آنالیز، گزینهی Descriptive Statistics که به معنی آمار توصیفی است را انتخاب کنید و روی OK کلیک کنید.
روی فیلد Input Range کلیک کنید و محدودهای که اعداد و آمار را وارد کردهاید با کلیک کردن روی سلول ابتدا و درگ کردن تا آخرین سلول، انتخاب کنید.
تیک گزینهی Labels in first row را بزنید تا تیترها در اولین ردیف اضافه شود.
از طریق فیلد Output Range نیز سلولهای حاوی نتایج آنالیز را انتخاب کنید. میتوان از گزینههای New Worksheet Ply و New Workbook نیز برای درج کردن نتیجه در صفحهای دیگر یا در فایل جدید، استفاده کرد.
برای دریافت جمعبندی آماری، تیک Summary statistics را بزنید.
در نهایت روی OK کلیک کنید تا پنجرهی Descriptive Statistics بسته شود و خروجی را مشاهده کنید.
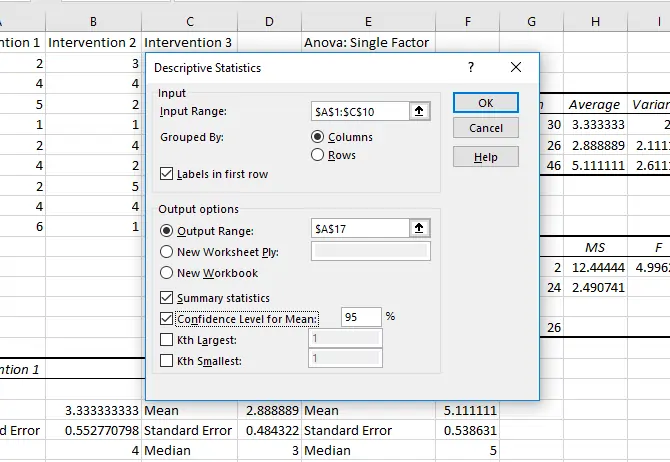
نتیجه را مشاهده کنید:
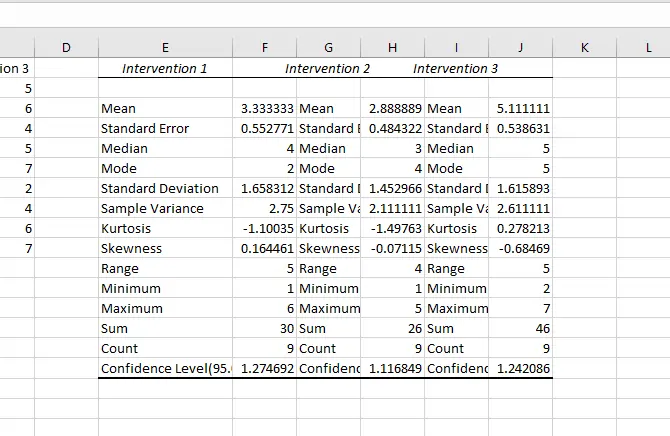
آنالیز آمار در اکسل با انواع t-Test: دو اندازهگیری از یک یا دو جامعهی آماری
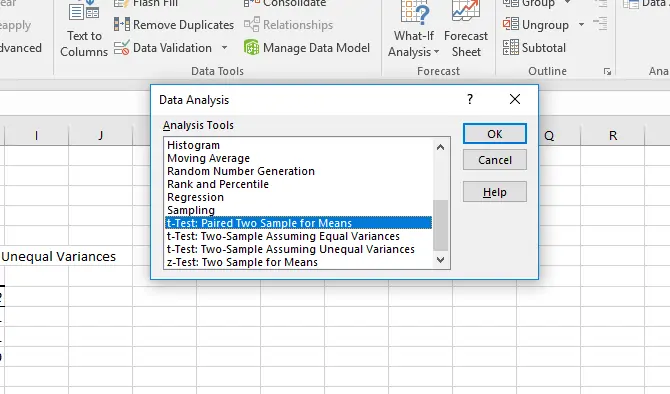
در ابزار تحلیل دادهی اکسل برای مقایسه کردن دو گروه داده، سه نوع t-Test تعریف شده است. پس از کلیک کردن روی ابزار Data Analysis در تب Data، یکی از سه حالت زیر را به تناسب نیاز انتخاب کنید و روی OK کلیک کنید.
- فرض کنید که قرار است دو مجموعه داده که مربوط به یک جامعهی آماری در دو زمان مختلف است را مقایسه کنید. به عنوان مثال فشار خون دانشآموزان یک کلاس قبل و پس از یک رویداد و آزمایش را مقایسه و تحلیل کنید. در این صورت میتوان از t-Test: Paired Two Sample for Means استفاده کرد.
- حالت دوم این است که بخواهیم دو گروه داده مربوط به اندازهگیری در دو جامعهی آماری متفاوت و مستقل را مقایسه کنیم. به عنوان مثال فشار خون دانشآموزان دو کلاس. در این صورت حالت t-Test: Two-Sample Assuming Equal Variances را انتخاب کنید و کمی بعد در مورد Equal Variances یا واریانس برابر نیز صحبت میکنیم.
- حالت سوم این است که دو گروه داده مربوط به دو جامعهی آماری داریم به طوری که واریانس نیز مساوی نیست. در این صورت t-Test سوم یعنی t-Test: Two-Sample Assuming Unequal Variances را انتخاب کنید.
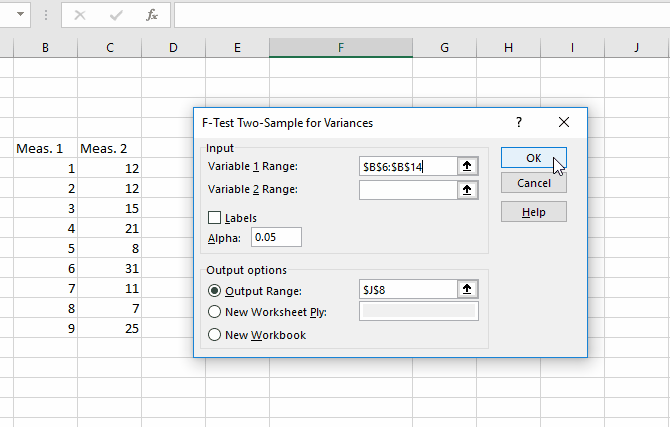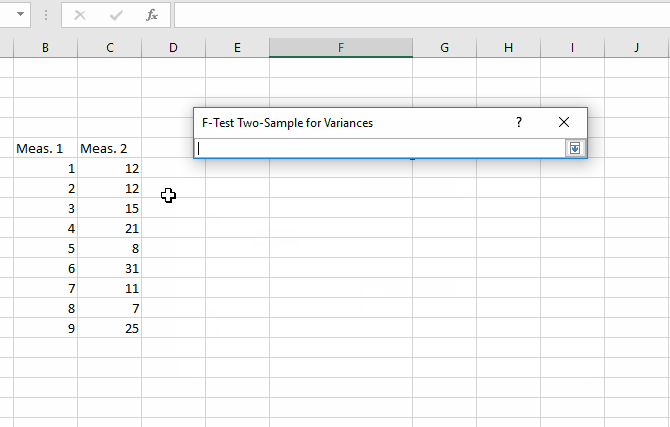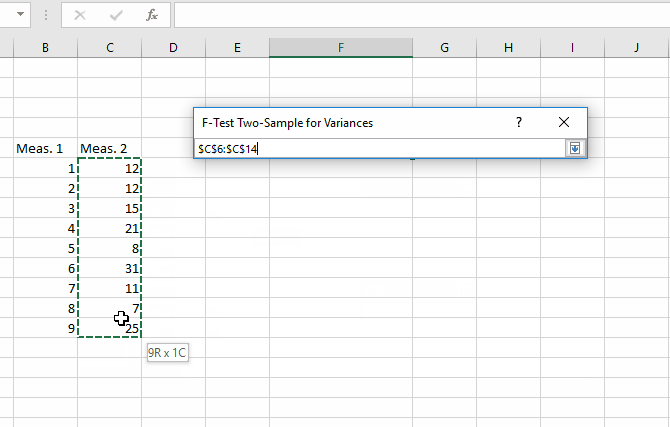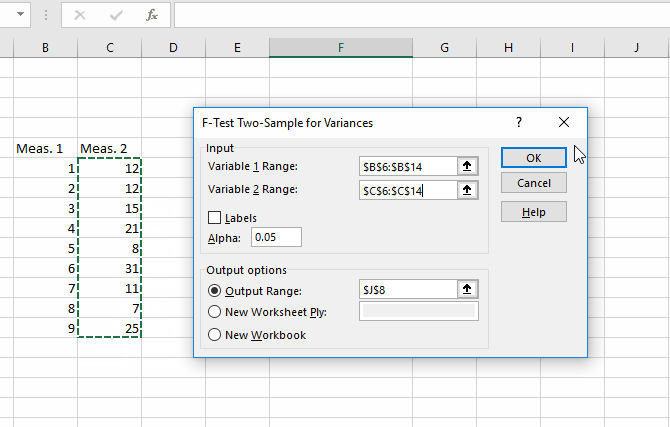
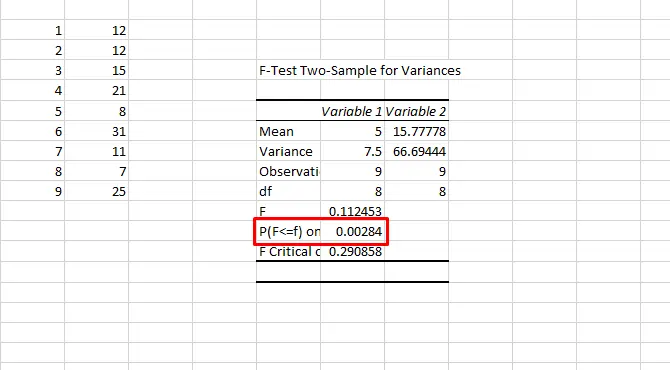
برای اینکه متوجه شویم که واریانس یا پراکندگی دو دسته دادهای که تهیه شده، مساوی است یا خیر و در نتیجه بین انتخاب گزینهی دوم یا سوم تصمیمگیری کنیم، به یک تست ساده نیاز داریم. بنابراین ابتدا وی ابزار Data Analysis در تب Data کلیک کنید و گزینهی F-Test Two-Sample for Variances را انتخاب کنید. دو گروه دیتا را با کلیک کردن روی فیلد Variable 1 Range و Variable 2 Range و روش کلیک و درگ کردن روی سلولها، انتخاب کنید. در نهایت روی OK کلیک کنید. اکسل نتیجه را در صفحهی جدیدی نشان میدهد مگر آنکه محل خروجی را از طریق فیلد Output Range در صفحهی فعلی انتخاب کرده باشید.
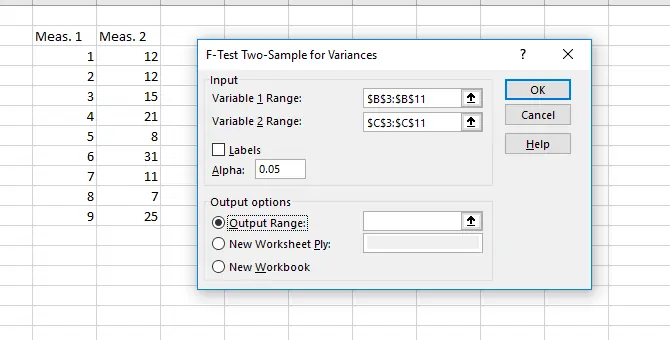
به مقدار P-Value توجه کنید، اگر این عدد کوچکتر از ۰.۰۵ باشد، به این معنی است که واریانس دو دسته دیتای شما یکسان نیست و باید از t-Test سوم استفاده کرد.
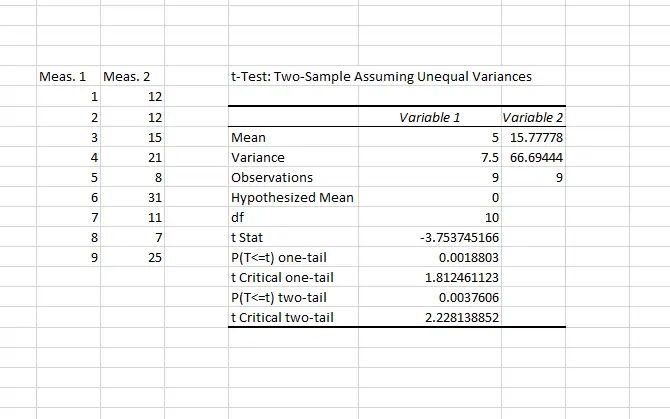
و اما به t-Testها برگردیم. پس از انتخاب کردن نوع آنالیز t-Test، دو دسته دادهی خود را مشابه F-test انتخاب کنید و محل درج کردن نتیجهی تحلیل را نیز مشخص کنید. روی OK کلیک کنید تا نتیجهی آنالیز شامل مقدار متوسط، انحراف و ... نمایش داده شود. به عنوان مثال اگر مقدار P کمتر از ۰.۰۵ واحد باشد، دو گروه داده کاملاً متفاوت هستند و میتوان نتیجه گرفت که دانشآموزان کلاس اول و دوم، وضعیت کاملاً متفاوتی دارند و باید به دنبال علت تفاوت بود.
آنالیز واریانس یا ANOVA به سه روش مختلف در Excel مایکروسافت
در اکسل میتوان از سه روش مختلف برای تحلیل کردن واریانس یا پراکندگی داده استفاده کرد. البته تستهای بعدی که تحلیلگران آمار پس از آنالیز واریانس انجام میدهند، در افزونهی Data Analysis اکسل پیشبینی نشده است.
و اما سه نوع تحلیل واریانس در اکسل:
- برای آنالیز کردن واریانس در حالتی که یک متغیر وابسته و یک متغیر مستقل داریم، حالت ANOVA: Single Factor کاربرد دارد. به عنوان مثال متغیر وابسته فشار خون است و متغیر مستقل میزان مصرف نمک یا وزن شخص است.
- برای تحلیل کردن واریانس دو گروه داده که مستقل هستند از ANOVA: Two-Factor with Replication استفاده میشود. مثل دو بار اندازهگیری فشار خون دانشآموزان یک کلاس که هیچ ارتباط خاصی وجود ندارد.
- برای تحلیل کردن واریانس در حالتی که دو متغیر مستقل داریم و در اندازهگیری، دیتای کپی وجود ندارد از ANOVA: Two-Factor without Replication استفاده میشود.
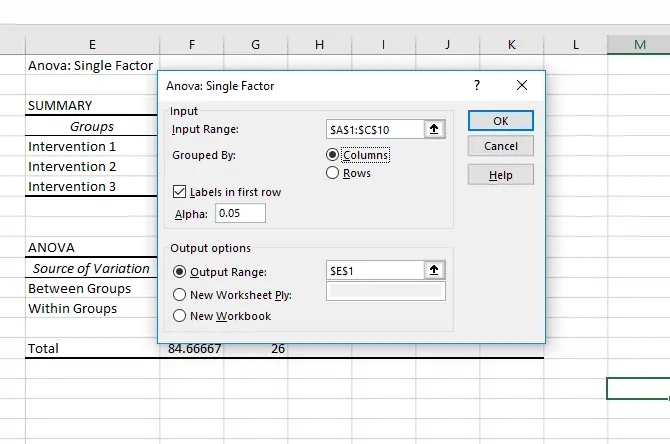
با یک مثال ساده کار با ابزار آنالیز واریانس را بررسی میکنیم و حالت اول را توضیح میدهیم. سه گروه دیتا به نام Intervention 1 الی Intervention 3 را در نظر بگیرید که هر یک در یک ستون مجزا وارد شده است. میتوان از ردیفها نیز برای وارد کردن دیتا استفاده کرد. روی ابزار Data Analysis کلیک کرده و حالت ANOVA: Single Factor را انتخاب کنید.
در فیلد Input Range، محدودهای که سه ستون حاوی دیتا قرار دارد را انتخاب کنید. با توجه به اینکه دادهها به صورت ستونی هستند، گزینهی Columns را انتخاب کنید. در مورد دادههای ردیفی باید Rows را انتخاب کرد.
از فیلد Output Range نیز محلی برای نمایش نتیجهی تحلیل واریانس انتخاب کنید.
با کلیک کردن روی دکمهی OK، نتیجه به صورت زیر خواهد بود:
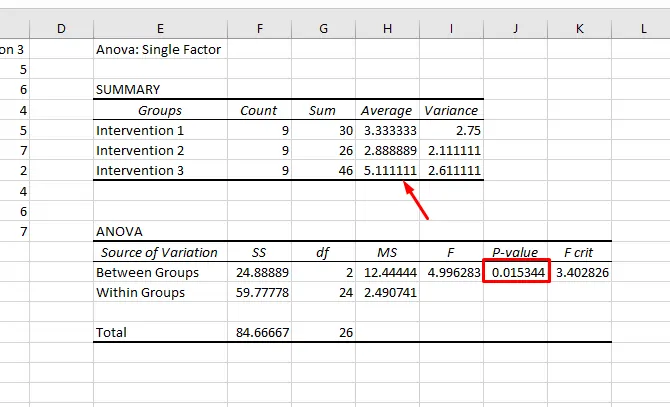
با توجه به اینکه P-Value کوچکتر از ۰.۰۵ است، تفاوت بین دو گروه از اطلاعات آماری تهیهشده، زیاد بوده است اما اکسل دقیقاً مشخص نمیکند که کدام گروه دیتا، تفاوت زیادی داشته است. بنابراین به مقدار متوسط سه گروه دیتا دقت کنید. در این مثال روشن است که گروه سوم یا Intervention 3 با دو گروه دیگر کاملاً متفاوت است اما صرفاً با توجه به میانگین دادهها نباید همیشه اینگونه نتیجهگیری کرد.
آنالیز ارتباط دادهها یا Correlation در اکسل
در اکسل میتوان ارتباط بین دادهها را با محاسبهی ضریب همبستگی یا Correlation متوجه شد. اگر حاصل این محاسبه، عدد ۱ باشد، به این معنی است که دو گروه داده کاملاً شبیه به هم هستند و اگر مقادیر کمتر باشد، تفاوتهایی وجود دارد.
به عنوان مثال اگر دو گروه دادهی X و Y به صورت زیر باشند و با هم کم و زیاد شوند، همبستگی کامل هست و ضریب همبستگی ۱ خواهد بود.
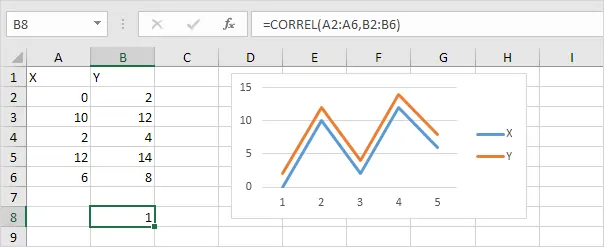
و حالت برعکس زمانی است که افزایش و کاهش X و Y کاملاً مخالف است و ضریب همبستگی منفی ۱ میشود:
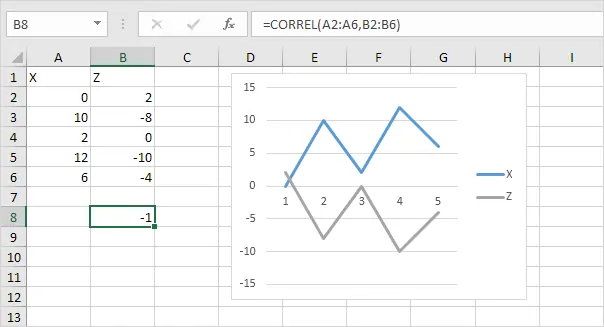
تحلیل همبستگی یا Correlation در اکسل با استفاده از تابع CORREL نیز صورت میگیرد اما بهتر است از ابزار Data Analysis استفاده کنید.
با اجرا کردن این ابزار از تب Data اکسل و انتخاب گزینهی Correlation، یک پنجرهی ساده نمایان میشود.
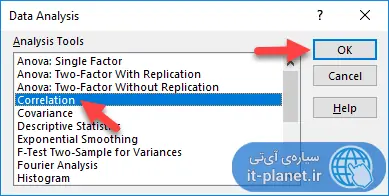
مثل همیشه از فیلد Input Range برای انتخاب کردن ستونها یا سطرهای حاوی دیتا استفاده کنید.
نوع ستونی یا ردیفی بودن دادهها را نیز به کمک Columns یا Rows زیر این فیلد، مشخص کنید.
در صورت نیاز تیک Label in first row را بزنید تا تیتر ستونها و سطرها را در جدول ضرایب همبستگی مشاهده کنید.
در نهایت از فیلد Output Range برای انتخاب کردن محل نمایش خروجی آنالیز همبستگی دیتا، استفاده کنید.
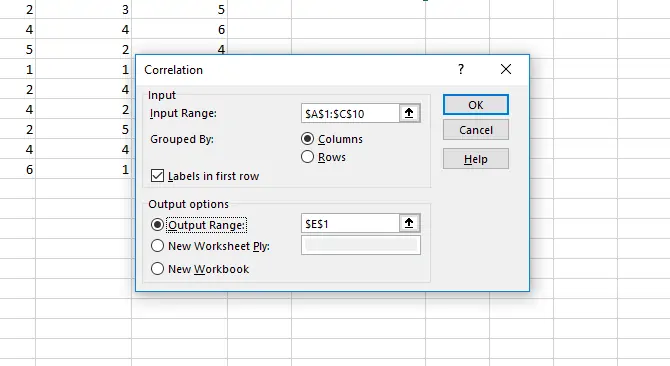
پس از کلیک کردن روی OK، نتیجه در مورد سه گروه دیتای ما به این صورت خواهد بود.
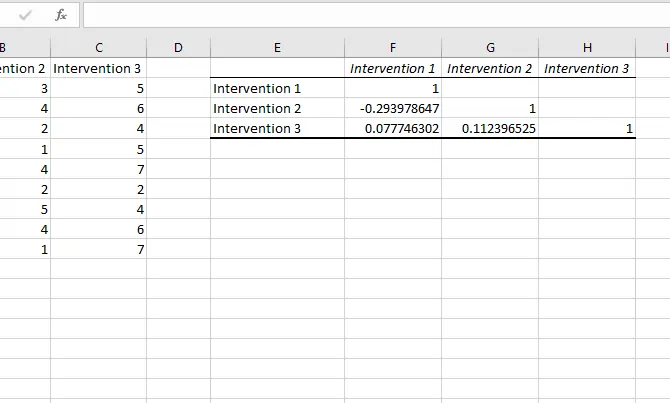
طبیعی است که اعداد روی قطر جدول مربعی که خروجی تحلیل را نشان میدهد، ۱ است چرا که مقایسهی یک گروه داده با خودش، به معنی شباهت کامل است. همانطور که مشاهده میکنید بین گروه دوم و اول، همبستگی حداقل است و ضریب محاسبه شده، کوچکترین مقدار (منفی) است.
تحلیل رگرسیون در اکسل برای شناسایی عوامل موثر روی پدیدهها
یکی از تحلیلهای پرکاربرد در علم آمار، Regression است. با استفاده از Regression میتوان مشخص کرد که چه عواملی اثر زیادی روی پدیدهها دارند. به عنوان مثال فرض کنید که متغیر وابستهی ما، فشار خون دانشآموزان است و متغیر مستقل نیز میزان نمک و وزن است. سوال این است که مصرف نمک اثر بیشتری روی فشار خون دارد یا میزان وزن شخص. برای تصمیمگیری در این مورد از رگرسیون استفاده میکنیم.
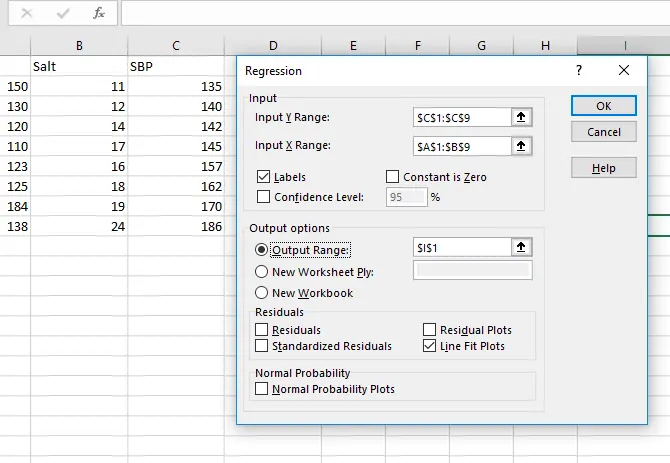
طبق معمولی روی Data Analysis در تب Data کلیک کنید و نوع تحلیل را Regression انتخاب کرده و روی OK کلیک کنید.
در پنجرهی محاسبهی Regression دو فیلد Input Y Range و Input X Range وجود دارد. فیلد Y برای انتخاب کردن دادههای وابسته که در مثال ما فشار خون است به کار میرود و فیلد دوم یعنی X برای انتخاب کردن گروههای دیتای مستقل مثل نمک، وزن، قد و ... استفاده میشود.
در صورت نیاز به برچسب برای مشخص بودن تیترها، تیک Labels را بزنید.
در بخش Output options نیز از فیلد Output Range سلول مقصد را انتخاب کنید.
در نهایت روی OK کلیک کنید.
خروجی کار به صورت زیر است، به مقدار P-Value برای دو گروه دیتای وزن یا Weight و نمک یا Salt دقت کنید:
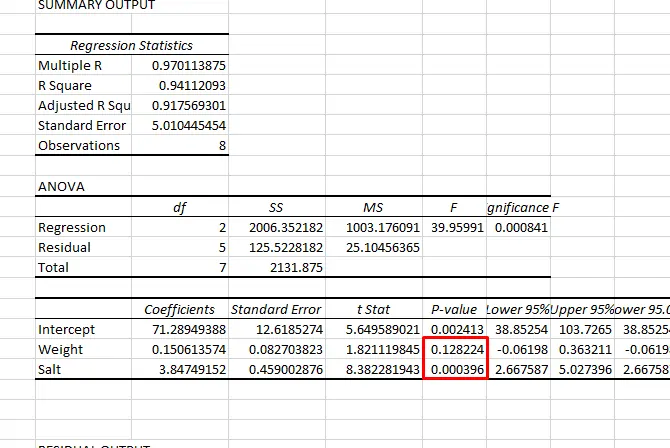
همانطور که مشاهده میکنید عدد P در مورد متغیر مستقل نمک بسیار کوچکتر از ۰.۰۵ است و این یعنی ارتباط تنگاتنگی بین فشار خون و میزان مصرف نمک وجود دارد در حالی که در مورد متغیر وزن، این عدد بزرگتر از ۰.۰۵ است که به معنی اثر کم آن روی فشار خون است.
makeuseofسیارهی آیتی
وایییییی فوق العاده دقیق و خوب توضیح دادید…واقعا مرسی خیلی واسم کارا بود و کلی از سوالاتم رفع شد
واقعا مچکرم تو کلی سایت دنبال این تحلیل داده ها بودم ولی درست و دقیق نتونسته بودم پیداش کنم همچنین که با تصویر توضیح دادید خیلی خوب و کارا بود .به امید موفقیت روزافزون
عالییییییییییییییی
با سلام برای تحلیل عاملی اکتشافی هم توضیحی لطف می فرمایید