

فشردهسازی ویدیو پیچیدهتر از فشردهسازی تصویر است چرا که ویدیوی خام حاصل پشت هم قرار دادن تعدادی عکس یا فریم است و برای کاهش حجم، میبایست فریمها را بررسی کرد و با روشهای پیچیده، شباهت فریمها را بررسی کرد و بخشهای مشابه را از فریمهای مختلف حذف کرد.
در این مقاله اشارهای مختصر به الگوریتمهای امروزی فشردهسازی ویدیو خواهیم داشت. با ما باشید.
لزوم فشردهسازی مولتیمدیا
عکسها و ویدیوها و صداهایی که فشرده نشده باشند، حجم بسیار زیادی اشغال میکنند. به عنوان مثال یک فایل عکس خام یا RAW تقریباً ۲ الی ۴ برابر عکسی با فرمت JPG فضا اشغال میکند. حتی عکسهای JPG که دوربینها ارایه میکنند را میتوان با افت نسبتاً کم کیفیت، کمحجمتر کرد. در این صورت شاید کیفیت عکس کمی کاهش پیدا کند اما در مقابل حجم فایل عکس ممکن است ۱۰ برابر کمتر شود!
در مورد ویدیوها نیز ویدیوی خام بسیار حجیم است. شاید یک دقیقه ویدیوی خام با رزولوشن نسبتاً پایین، بیش از ۱ گیگابایت فضا اشغال کند! در حالی که فشردهسازی موجب شده که حجم فیلمهایی که در فضای وب برای دانلود ارایه میشود، کمتر از ۲ گیگابایت باشد.
همانطور که اشاره کردیم فشردهسازی ویدیو مثل فشردهسازی عکس نیست. برای فشرده کردن یک عکس خام یا RAW، میتوانید صرفاً نویز بخشهای یکدست و تکرنگ را حذف کنید. با همین روش ساده، حجم عکس به شدت کاهش پیدا میکند اما در مورد ویدیو باید زمان و فریمهایی که پس از فریم فعلی نمایش داده میشود را در نظر گرفت. الگوریتمهای فشردهسازی ویدیو موثرتر و پیچیدهتر است.
فرمت متداول برای فشردهسازی ویدیو در سالهای اخیر، H.264 بوده و تدریجاً استفاده از H.265 متداول میشود. اما اصول و اساس فشردهسازی نسبتاً یکسان است. لذا در ادامه اصول فشردهسازی ویدیو با فرمت H.264 را بررسی میکنیم.
فشردهسازی چیست؟
فشردهسازی ویدیو به معنی حذف کردن اطلاعات تکراری کلی یا لحظهای و اطلاعات غیرمهم است. با حذف کردن اطلاعات تکراری و در واقع یک بار استفاده از این اطلاعات به جای چند بار، حجم ویدیو به مراتب کمتر خواهد شد.
به عنوان مثال فرض کنید در ویدیویی، چهرهی شخصی در حال صحبت کردن روی پسزمینه که ثابت است، دیده میشود. ممکن است صورت شخص در موقعیت نسبتاً ثابتی قرار گرفته باشد و تنها بخشهایی مثل چشم و لبها حرکت کند. در این صورت در تمام فریمها، نیازی به اطلاعات تمام بخشهای تصویر نیست. میتوان یک فریم کامل شامل پسزمینه و اطراف چهره را قرار داد و در فریمهای بعدی بخشی که تغییر کرده یعنی لبها و چشم را ذخیره کرد. با این روش ممکن است حجم اطلاعات لازم برای بازسازی فریمهای مجزای ویدیو، دهها برابر کمتر شود.
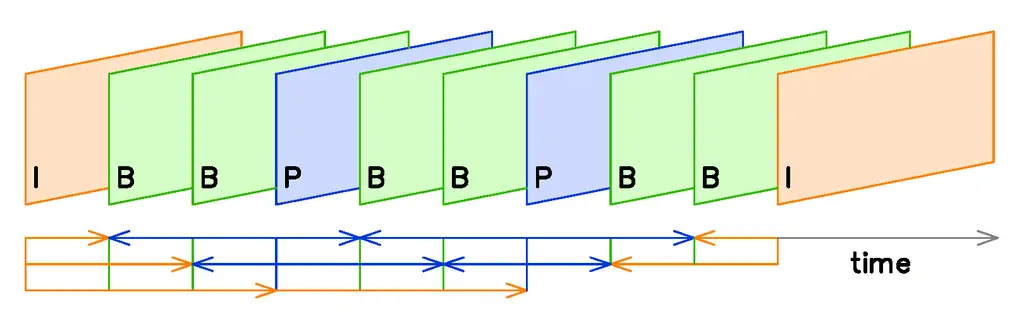
به فریمی که به عنوان مرجع برای ساختن فریمهای بعدی استفاده میشود، intraframe گفته میشود. سایر فریمها نیز به انواعی به اسم B و P تقسیم میشوند که در ادامه با مفهوم این انواع بیشتر آشنا میشویم.
مفهوم I-frames و P-frames و B-frames
با توضیحاتی که پیشتر دادیم، روشن است که I-frame یا فریم i، یک فریم با دیتای کامل است و در واقع تصویری است که از ویدیوی اصلی استخراج شده و با توجه به متفاوت بودن آن با فریمهای قبلی، به عنوان یک فریم کامل در ویدیو استفاده میشود. این فریم حجم بالاتری نسبت به سایر فریمها دارد.
اما فریمهای بین فریمهای i: این فریمها با استفاده از اطلاعات موجود در فریمهای i ساخته میشوند. در واقع زمانی که ویدیو را در ویدیو پلیر Play میکنید، عمل بازسازی فریمها آغاز میشود.
فریمهای میانی به دو نوع تقسیم میشوند:
- برخی فریمها صرفاً با استفاده از اطلاعات فریم i قبلی ساخته میشوند. به این فریمها P-frame گفته میشود.
- برخی از فریمها حاصل ترکیب کردن اطلاعاتی از فریم P قبلی و فریم i بعدی هستند که به آنها B-frame گفته میشود. حرف B مخفف bi-directionally predicted یا پیشبینی دوجهته است.
اما یک مثال ساده برای روشن شدن مفهوم سه نوع فریم I و P و B:
فرض کنید یک دایرهی نقطهخوار داریم! نقطهها در صفی حرکت میکنند و دایره آنها را میبلعد. در شروع چنین ویدیویی، یک فریم i داریم که شامل همهچیز است.
پس از لحظاتی صف نقطهها کمی نزدیکتر میشوند. لذا یک فریم P ایجاد میکنیم و در آن فقط موقعیت جدید صف نقطهها را ذکر میکنیم. همانطور که در تصویر زیر مشاهده میکنید، فعلاً تعداد نقاط سه عدد است، درست مثل فریم i قبلی.
پس از لحظاتی یک نقطهی جدید در انتهای صف ظاهر میشود. موقعیت این نقطه را از فریم i بعدی محاسبه میکنیم و لذا این فریم، یک فریم B است چرا که به موقعیت نقاط در فریم P قبلی و همینطور نقطهی چهارم در فریم i بعدی نیاز دارد.

اینکدر و اینکد کردن فریمهای I و P و B
برای فشرده کردن فریمهای I میتوان مشابه روشهای فشردهسازی عکسها اقدام کرد. این فریمها یک تصویر کامل هستند لذا میتوان مثل عکسهایی با فرمت JPG، فشردهسازی ویدیو را انجام داد. معمولاً فشردهسازی عکسها در فضای رنگ YCbCr انجام میشود که در این فضای رنگ، روشنایی یک پارامتر است و دو پارامتر دیگر رنگ را مشخص میکند.
در روشهای قدیمی فشردهسازی ویدیو که شناسایی حرکت سوژهها و در حالت کلی، الگوریتمهای پیشبینی وجود نداشت، بازدهی به مراتب پایینتر بود. لذا ویدیوهایی با فرمت DV یا Motion JPG، حجم بالایی دارند.
در الگوریتمهای امروزی فشردهسازی ویدیو مثل H.264، فریمهای مرجع که I-frame نامیده شده، به صورت هوشمندانه در موقعیتهای زمانی مختلف چیده میشوند. هر چه فاصلهی این فریمها بیشتر باشد، طبعاً فشردهسازی بیشتر خواهد شد اما اگر فاصله بیش از حد زیاد باشد، افت کیفیت قابل توجه میشود. اینکه فاصله چقدر باشد و هر یک از فریمهای i از نظر جزئیات تصویر، چقدر شبیه به ویدیوی اصلی باشد، توسط اینکدر ویدیو به صورت هوشمندانه محاسبه میشود.
برای فشردهسازی ویدیو با فرمت H.264 که یک استاندارد کلی است، چندین اینکدر مختلف و معروف موجود است. در حال حاضر معروفترین و بهترین Encoder که به خصوص برای فشرده کردن فیلمها در فضای وب استفاده میشود، x264 است.
تعداد فریمهای P و B و اینکه در چه زمانی از چه فریمی استفاده شود هم توسط اینکدر به صورت هوشمندانه مشخص میشود. هر چه پیشبینی و تخمین اینکدر به ویدیوی اصلی نزدیکتر باشد، طبعاً کیفیت ویدیوی فشرده شده به ویدیوی اصلی نزدیکتر خواهد بود. به همین جهت است که با تغییر دادن تنظیمات در نرمافزارهای Convert ویدیو یا نرمافزارهای ویرایش ویدیو، محل و تعداد فریمهای B و P نیز تغییر میکند.

در استاندارد H.264 سطح ویدیو به بخشهایی به اسم ماکروبلاک یا بلوکهای بزرگ تقسیم میشود. معمولاً ابعاد این ماکروبلاکها، ۱۶ در ۱۶ نمونه است. الگوریتمهایی ویدیو را پردازش میکنند و تلاش میشود که تشابه بین بلوکهای فریم فعلی با فریمهای قبلی که در واقع فریم مرجع یا Reference Frame هستند، شناسایی شود. اگر تشابهی پیدا شود، رابطهی ریاضی بین ماکروبلاک فعلی با آنچه در فریم مرجع موجود است، محاسبه میشود. در واقع رابطهی ریاضی یک بردار حرکتی یا Motion Vector است که مشخص میکند بلوکها در ویدیو، در چه جهتی حرکت کردهاند.
حین پخش کردن ویدیو، فریم مرجع با در نظر گرفتن بردارهای حرکتی تغییر شکل میدهد و فریمهای بعدی ساخته میشود. این کار به پردازشی نسبتاً سنگین نیاز دارد که بهتر است توسط شتابدهی سختافزاری به کمک پردازندهی گرافیکی یا GPU انجام شود و نه پردازندهی اصلی یا CPU.
در برخی CPUها و GPUها، واحدی به اسم موتور مولتیمدیا وجود دارد که برای پردازش بهینه و سریع این امور طراحی شده است و با کمترین مصرف برق، دیکد ویدیو انجام میشود.
maketecheasierسیارهی آیتی